



How Machine Learning Is Taking Catastrophe Modeling to a New Level
Dec 16, 2020
Today’s insurance industry can trace its origins back to the 1600s and is steeped in tradition, but it is now in the process of undergoing unprecedented change driven by market forces and technology. Massive amounts of data are being generated and increasingly, data science is enabling advances in catastrophe modeling.
What Is Machine Learning?
Artificial Intelligence (AI) is not a new concept—the term was coined in the 1950s—but its practical applications have expanded in tandem with the dramatic growth in computing power in recent years and are in widespread use today. Described as “the simulation of human intelligence in machines that are programmed to think like humans and mimic their actions,” it is a truly vast field within computer science.i As the Brookings Institution noted, “AI-based computer systems can learn from data, text, or images and make intentional and intelligent decisions based on that analysis.”ii
 Samyadeep Ghosh
Samyadeep Ghosh
Lead Research Engineer
 Åsa Bergman
Åsa Bergman
Senior Analyst II
 Boyko Dodov, Ph.D.
Boyko Dodov, Ph.D.
Vice President and Director
Edited by Jonathan Kinghorn, CEEM
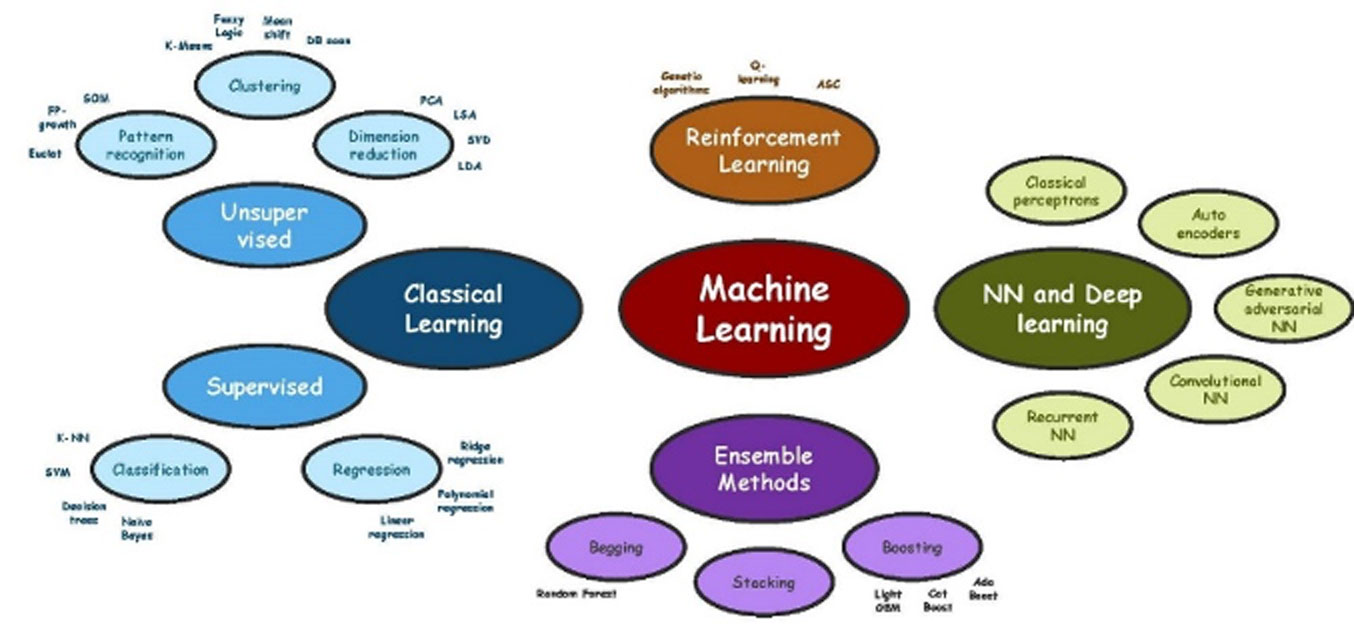
Machine Learning (ML) is generally considered to be the core, or the heart of AI (Figure 1). As the name suggests, it is concerned with a universe of programmed algorithms and software that “can learn from data without relying on rules-based programming.”iii Put another way, its flexible and, in general, non-linear models use computer algorithms to learn and extract dependencies and rules from data, based on which they can make decisions or predictions that they were not specifically programmed to make.
ML is particularly useful for assessing "big data" sets, where each data element tells a bit more about the other elements. As it learns what dependencies should get more weight in relation to other factors, ML helps sift through vast amounts of what may be competing data to find information that a human analyst would not have the time to look for. ML is expanding rapidly as a field as more data becomes available and more algorithms are developed, and this growth shows no signs of slowing down. Its potential applications are many and varied, with some branches being developed for image processing and others for language processing, to cite just two of innumerable examples.
Since its inception the catastrophe modeling industry has largely focused on traditional statistical techniques, but it is now alert to the potential of ML. In traditional catastrophe models data is used for calibration and validation. In data-assisted models for natural catastrophes, physical models are used to better understand and simulate the underlying process. The complexity of the physical descriptions used is dependent on the availability of computing resources, speed requirements, and/or input data. To make the models run faster, simplifications are used to replace the "first principle" physics with statistical/empirical/ML/heuristic relationships. AIR is already exploring and implementing ML-based approaches in a wide range of problems covering the entire spectrum of catastrophe models—from hazard and exposure in property and casualty, to life and cyber. The next three sections each describe one example, chosen from among many.
Tropical Cyclone Precipitation Simulation
To provide a reliable representation of the risk from tropical cyclone–induced floods, one needs to conduct high spatial and temporal resolution simulations for tens, and even hundreds of thousands of seasons under specific climate conditions. Ultimately, this could be done by using a numerical weather prediction (NWP) model, but this approach is not feasible in the catastrophe modeling context and, most importantly, may not provide tropical cyclone (TC) tracks consistent with observations. Rather, AIR leverages ensembles of NWP output of past TC precipitation patterns (in terms of NWP downscaled reanalysis) collected on a Lagrangian frame (a coordinate system moving with the eye of the cyclone along the historical TC tracks). The ensembles from all 6-hourly simulation periods are then considered as a “dictionary” of stochastic models.
Provided that the stochastic storm tracks with all the parameters describing the TC evolution are already simulated as a part of AIR’s TC models worldwide, a sequence of samples from the dictionary is chosen conditionally on the TC characteristics at a given moment in space and time. The samples are concatenated using a data assimilation technique, producing a continuous non-stationary precipitation pattern on a Lagrangian frame. The simulated precipitation for each event is finally distributed along the stochastic TC track and blended with a non-TC background precipitation simulated separately. This proposed framework provides highly efficient simulations (100,000 seasons simulated within a couple of weeks) of robust TC precipitation patterns consistent with observed regional climate and visually undistinguishable from high-resolution NWP output. The framework is used to simulate the TC-induced precipitation for AIR’s Japan and U.S. flood models. An illustration of the methodology is presented in Figure 2.
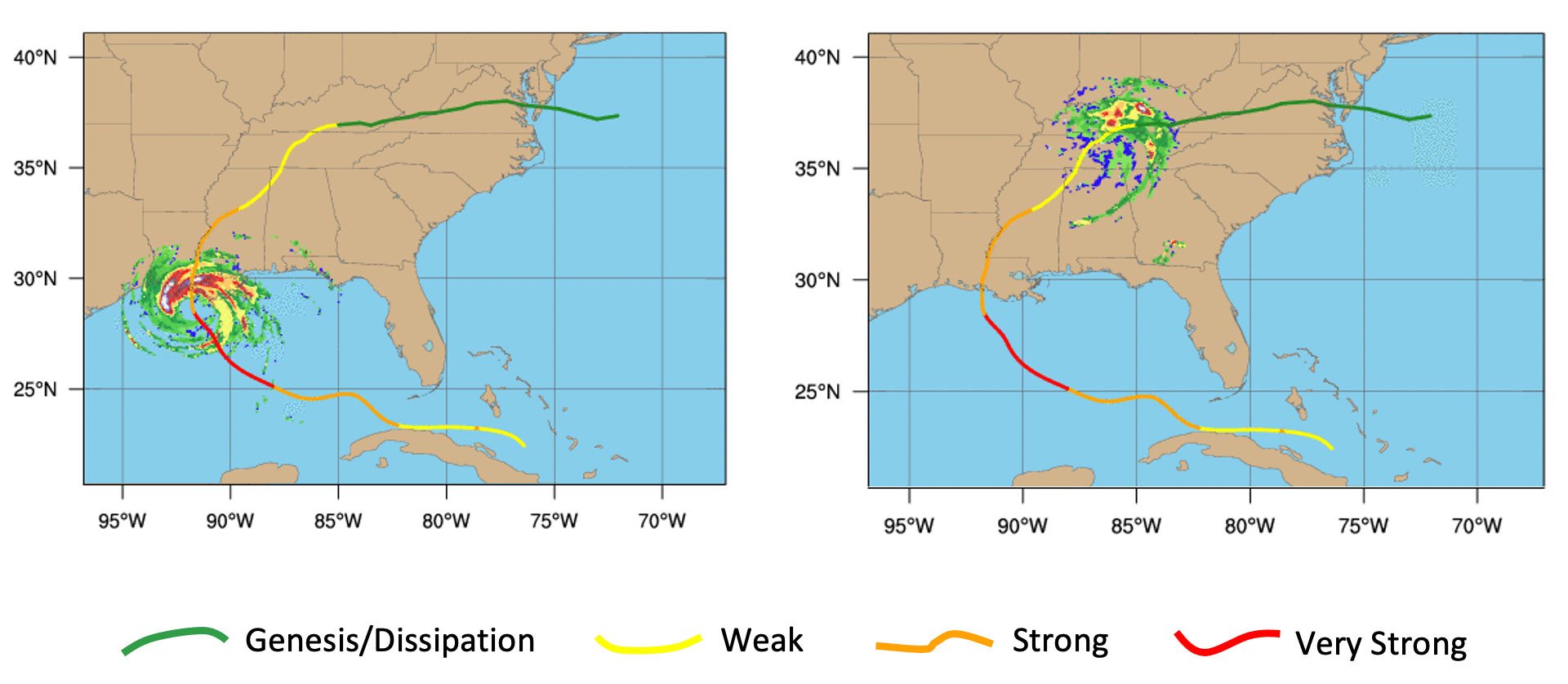 Figure 2. Example of TC precipitation simulation for a synthetic stochastic track at different stages of its evolution. Different stochastic models are chosen from the “dictionary” to simulate 6-hourly intervals of the TC precipitation pattern evolution. (Source: AIR)
Figure 2. Example of TC precipitation simulation for a synthetic stochastic track at different stages of its evolution. Different stochastic models are chosen from the “dictionary” to simulate 6-hourly intervals of the TC precipitation pattern evolution. (Source: AIR)Simulating the Behavior of Major Reservoirs
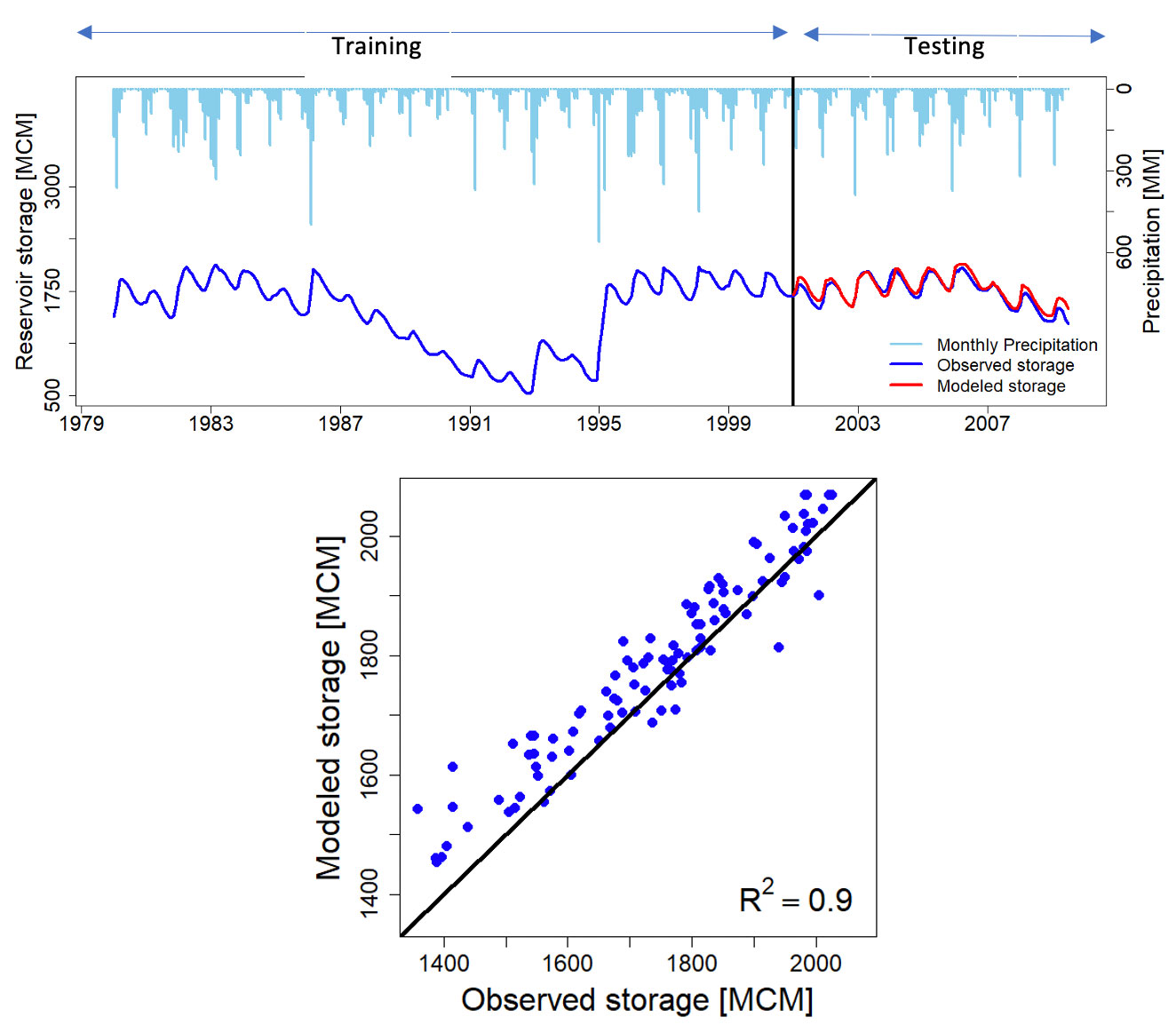
Lakes and reservoirs designed for flood attenuation can significantly affect flow variability and decrease the magnitude of flood peaks. The flow of water out of them is generally managed by employing operational rule curves (ORCs), which are based on characteristics such as climate and the reservoir’s intended use; however, this information is not readily available for every reservoir. Furthermore, the large variability in ORCs between different dam types (e.g., irrigation, hydroelectric, etc.) and from year to year for the same reservoir makes it difficult to use generalized ORCs. AIR therefore developed an artificial neural network (ANN) model using the storage state data from the U.S. Geological Survey (USGS), U.S. Bureau of Reclamation, and precipitation data from the North American Land Data Assimilation System (NLDAS) to model ORCs across the United States.
A separate ANN model was trained for each of the 412 reservoirs initially selected and the architecture of the network (i.e., the number of hidden layers and the neurons in each layer) was optimized for each reservoir separately. One enhancement AIR introduced was the inclusion of two months of precipitation beyond the current modeled time step, which assumes reservoir operators will have information on precipitation forecasts and be able to adjust the reservoir operations accordingly. This is suitable for the stochastic simulation framework, as the precipitation for all months is readily available in advance.
The models were trained using resilient back propagation on the first 70% of the available time series; the remaining 30% was used for a testing phase. To validate the model, AIR used the trained ANN models to generate storage time series using historical rainfall data for 39 years from 1979 to 2017 and compared the storage time series to observed storage time series (Figure 3).
Exposure Data
Detecting and classifying features in imagery is one of the most successful and proven uses of deep learning/machine learning. AIR is exploring the use of ML on satellite imagery to locate clusters of high-rise buildings in parts of Asia where geospatial building data sets are not readily available. Visual identification in aerial imagery by analysts is possible, but not efficient for vast countries such as China. In a pilot project AIR used Sentinel-2 satellite imagery with 10-meter spatial resolution over South Korea and China and trained a convolutional neural network (CNN) algorithm on a set of previously identified high-rise buildings. As illustrated by the yellow grid cells in Figure 4, the algorithm flagged grid cells that with some likelihood contain high-rise buildings. Analogous to how our eyes can spot clusters of tall buildings in overhead imagery, the algorithm learns to identify possible high-rises from the shadows, patterns, and shapes found in the training data. This method yields a manageable number of cells that can be manually reviewed and further processed efficiently by an analyst.

AIR’s Applications of ML: What Does the Future Hold?
ML is emerging as a useful, though complex, tool that has to be applied carefully. The successful selection and application of ML algorithms depends upon a deep understanding of both the problem being addressed and the data available. Only with that understanding is it possible to figure out what kind of approach is most likely to be successful in meeting the objective. Complex testing parameters need to be addressed and the modeler must understand how to configure inputs in a way that makes sense.
The potential applications of ML are many and varied. AIR, as a catastrophe modeling company, is actively looking for opportunities to use ML applications in ways that will enhance the output of our models beyond what can be achieved with traditional statistical techniques. ML is already enabling us to extract information we would not otherwise be able to obtain with traditional approaches. Although this article has introduced three areas in which we are making use of this technology, we are also employing it in the cyber risk, life and pension risk, and data services arenas.
AIR is also using ML methodologies in a new generation of global atmospheric peril models.
i https://www.investopedia.com/terms/a/artificial-intelligence-ai.asp
ii https://www.brookings.edu/research/what-is-artificial-intelligence/, accesses 11/17/20
iii Dorian Pyle and Cristina San Jose, “An Executive’s Guide to Machine Learning,” McKinsey Quarterly, June, 2015.
